
본 포스트는 '트랜스포머를 이용한 자연어 처리 - 한빛미디어'를 읽고 리뷰한 글입니다.
토큰화(Tokenization)
딥러닝 모델은 숫자가 아닌 Apple과 같은 문자열을 그대로 이해하지 못합니다. 따라서 토큰화를 이용하여 문자열을 모델이 이해할 수 있는 숫자 리스트로 변환합니다.
이때 토큰은 더 이상 쪼갤수 없는 단위(리스트에 있는 각 요소)를 일컫으며, 토큰화는 토큰으로 문자열을 쪼개는 것을 의미합니다. 숫자로 바꾸는 과정을 수치화(Numericalization)이라 합니다. 조금 수식으로 단순화 해보자면, Input이 $S$라면 $f(S)$를 구하는 겁니다.
문자 토큰화(Character Tokenization)
문자 토큰화는 문자열 $S$에 있는 각 문자 $S_i$를 토큰으로 사용하는 토큰화 방법입니다.
예를 들어 $S$가 'Apple is good'이라면 토큰은 A, p, l, e, ' ', i, s, g, o, d (중복 제거)가 됩니다.
공백도 포함됩니다.
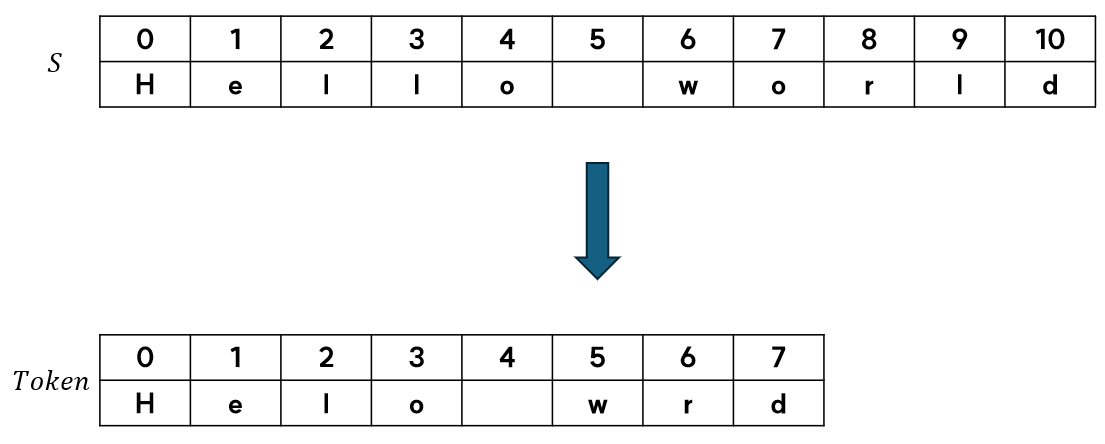
문자 토큰화의 장점은 철자 오류나 희귀한 단어를 처리하는 데 유용하지만, 단어 구조를 파악할 수 없다는 게 단점입니다.
단어 토큰화(Word Tokenization)
단어 토큰화는 문자열 $S$를 공백을 기준으로 잘라서 나온 단어를 토큰으로 사용하는 토큰화 방법입니다.
예를 들어 $S$가 'Apple is delicious.'이라면 토큰은 Apple, is, delicious.(온점 포함)이 됩니다.
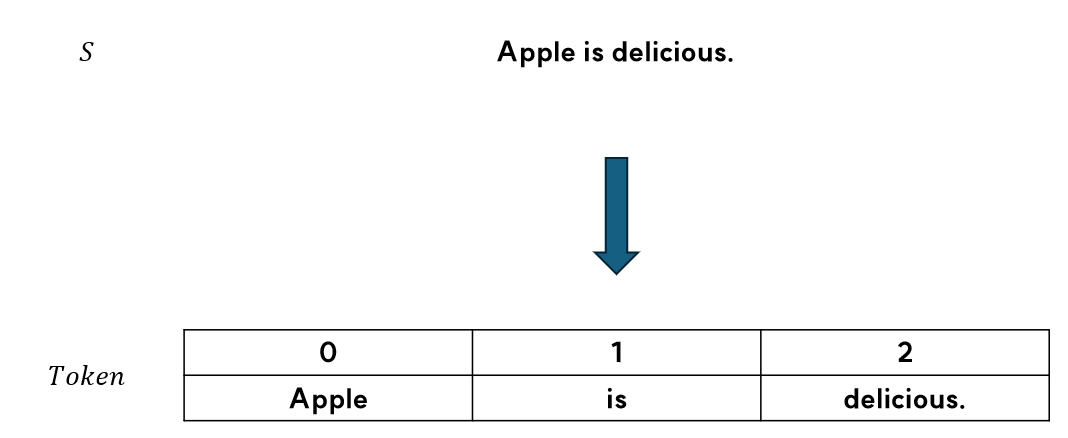
단어 토큰화의 장점은 문자에서 단어를 학습하는 과정이 생략되어 훈련 과정의 복잡도가 감소한다는 장점이 있지만, Apple과 Apple. 은 서로 다른 토큰으로 인식될 수 있는 점, eat같은 단어도 eat, eating, eats, eets(오타) 와 같이 여러 활용과 오타 등으로 인해 하나의 중심 의미에 여러개의 토큰이 생길 수 있다는 단점을 가지고 있습니다.
부분단어 토큰화(Subword Tokenization)
부분단어 토큰화는 문자 토큰화와 단어 토큰화의 장점을 결합한 방법으로 eat과 같이 자주 사용하는 단어가 아니라 eating, eats과 같은 단어를 각각 eat + -ing / eat + -s로 더 작은 단위로 쪼개는 방법입니다. 이 방법의 경우 오타나 복잡한 단어등을 처리하기에 용이해지게 됩니다.
부분단어 토큰화는 통계 규칙이나 알고리즘 등을 함께 사용해 사전 훈련된 말뭉치에서 학습된다는 차이점이 존재합니다.
'AI' 카테고리의 다른 글
| [자연어처리] 2. 쿼리(Query), 키(Key), 값(Value) (0) | 2024.09.18 |
|---|---|
| [AI - 2] 회귀의 시작 - 선형 회귀 (0) | 2024.01.25 |
| [AI - 1] 오차 함수 - 오차를 계산하자 (0) | 2024.01.20 |